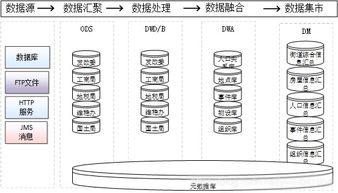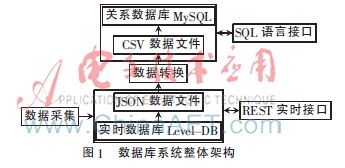
在微服務(wù)架構(gòu)中,查詢、數(shù)據(jù)處理和存儲(chǔ)支持服務(wù)是實(shí)現(xiàn)系統(tǒng)高效運(yùn)行的關(guān)鍵組成部分。它們不僅能夠提升系統(tǒng)的可擴(kuò)展性和可維護(hù)性,還能確保數(shù)據(jù)的一致性和可用性。以下將詳細(xì)探討這些服務(wù)在微服務(wù)環(huán)境中的實(shí)現(xiàn)方式及其重要性。
一、查詢服務(wù)
查詢服務(wù)負(fù)責(zé)處理用戶或系統(tǒng)的數(shù)據(jù)請求,通常通過 API 網(wǎng)關(guān)或?qū)S貌樵兎?wù)提供統(tǒng)一的入口。在微服務(wù)架構(gòu)中,查詢服務(wù)需要支持跨多個(gè)服務(wù)的復(fù)雜查詢,常見解決方案包括:
- API 組合模式:將多個(gè)微服務(wù)的查詢結(jié)果聚合,適用于簡單查詢場景。
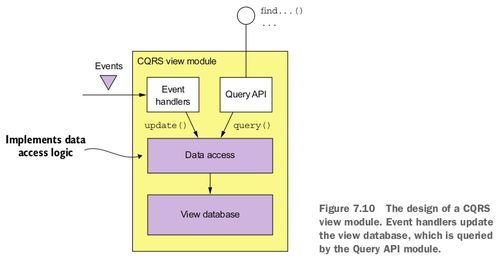
- CQRS(命令查詢職責(zé)分離)模式:將讀寫操作分離,通過獨(dú)立的查詢服務(wù)處理復(fù)雜查詢,提升查詢性能。
- 事件溯源:通過記錄事件序列來重構(gòu)數(shù)據(jù)狀態(tài),支持歷史查詢和審計(jì)。
二、數(shù)據(jù)處理服務(wù)
數(shù)據(jù)處理服務(wù)包括數(shù)據(jù)的轉(zhuǎn)換、驗(yàn)證、清洗和分析等功能,確保數(shù)據(jù)質(zhì)量和一致性。在微服務(wù)中,數(shù)據(jù)處理通常通過事件驅(qū)動(dòng)架構(gòu)實(shí)現(xiàn):
- 流式處理:利用 Kafka、Apache Flink 等工具實(shí)時(shí)處理數(shù)據(jù)流,支持實(shí)時(shí)分析和響應(yīng)。
- 批處理:使用 Spark 或 Hadoop 進(jìn)行大規(guī)模數(shù)據(jù)批量處理,適用于離線分析場景。
- 數(shù)據(jù)驗(yàn)證與清洗:在數(shù)據(jù)進(jìn)入存儲(chǔ)前進(jìn)行格式驗(yàn)證和去重,防止臟數(shù)據(jù)影響系統(tǒng)穩(wěn)定性。
三、存儲(chǔ)支持服務(wù)
存儲(chǔ)支持服務(wù)為微服務(wù)提供數(shù)據(jù)持久化和訪問能力,需根據(jù)數(shù)據(jù)類型和訪問模式選擇合適的存儲(chǔ)方案:
- 關(guān)系型數(shù)據(jù)庫:適用于事務(wù)性強(qiáng)的場景,如 MySQL、PostgreSQL,但需注意分庫分表以應(yīng)對(duì)擴(kuò)展性挑戰(zhàn)。
- NoSQL 數(shù)據(jù)庫:如 MongoDB(文檔型)、Redis(鍵值型)、Cassandra(列存儲(chǔ)),適用于高并發(fā)和靈活數(shù)據(jù)模型的需求。
- 分布式文件系統(tǒng):如 HDFS 或云存儲(chǔ)服務(wù),用于存儲(chǔ)大規(guī)模非結(jié)構(gòu)化數(shù)據(jù)。
- 數(shù)據(jù)同步與復(fù)制:通過 CDC(變更數(shù)據(jù)捕獲)或主從復(fù)制機(jī)制,確保數(shù)據(jù)在多個(gè)服務(wù)間的一致性。
四、集成與最佳實(shí)踐
在微服務(wù)架構(gòu)中,查詢、數(shù)據(jù)處理和存儲(chǔ)服務(wù)需要緊密集成,并遵循以下最佳實(shí)踐:
- 服務(wù)解耦:通過事件驅(qū)動(dòng)或消息隊(duì)列(如 RabbitMQ)降低服務(wù)間的直接依賴。
- 監(jiān)控與日志:使用 Prometheus、ELK 棧等工具監(jiān)控?cái)?shù)據(jù)流和存儲(chǔ)性能,及時(shí)發(fā)現(xiàn)問題。
- 安全與權(quán)限:實(shí)施數(shù)據(jù)加密和基于角色的訪問控制,保護(hù)敏感信息。
- 彈性設(shè)計(jì):通過斷路器、重試機(jī)制和備份策略,提升系統(tǒng)的容錯(cuò)能力。
微服務(wù)中的查詢、數(shù)據(jù)處理和存儲(chǔ)支持服務(wù)是構(gòu)建高可用、可擴(kuò)展系統(tǒng)的基石。通過合理的設(shè)計(jì)和工具選型,企業(yè)能夠應(yīng)對(duì)復(fù)雜業(yè)務(wù)需求,同時(shí)保障數(shù)據(jù)的高效管理和安全。